Google Docs to HTML

(In this tutorial, we will explore a quick way to re-purpose a Google word processing document for use on the web with validated code, using a trick that will help you produce clean code.)
Hey… have you used Google Documents lately? They’re getting more and more sophisticated with more and more reasons to use them for spreadsheet and word processing work, instead of Microsoft Office. Who cares… you’re a “WebMaster”, and you don’t use Word Processors to create your pages — right? Wait a minute, “big gun.” Sure, when your primary purpose is to code for the web, you probably would begin with a good coding tool (refer to our APTANA overview article, for a good open-source choice).
But even though Google produces ugly code (see below), there are some reasons why you might choose to start your web content writing there:
- Clients: You might have a client that provides copy using Google Documents, or another Word Processing program, where this same process will work for you. This will make you a “client-friendly” WebMaster.
- Focus on Writing: You might like to use the Document editing tools to focus on writing prior to creating a page — like using Google for Content Management (The Web IS your Content Management System).
- Auto Blog Posting: BlogMasters can use Google Docs to write and Edit stories, then automatically post them to your blog (after inputting some information about your blog).
- Collaboration: One great feature of Google Docs is the ability to see a “revision” for your document which represents each time it was saved — a great tool when you are collaborating with another editor or writer on the same document (The Web is a a CMS).
- Quickly Clean Code: You can quickly clean up the mess of code Google docs produces using the trick I’ll teach you here. This same trick will help you clean up code for any webpage!
Steps… here we go:
1. To follow along, get yourself a Google account (the spreadsheet and word processing tools are great), and create a sample document, at Docs.Google.com.
2. Create a test document — Google Docs allows you to insert tables and photos, so I did that:
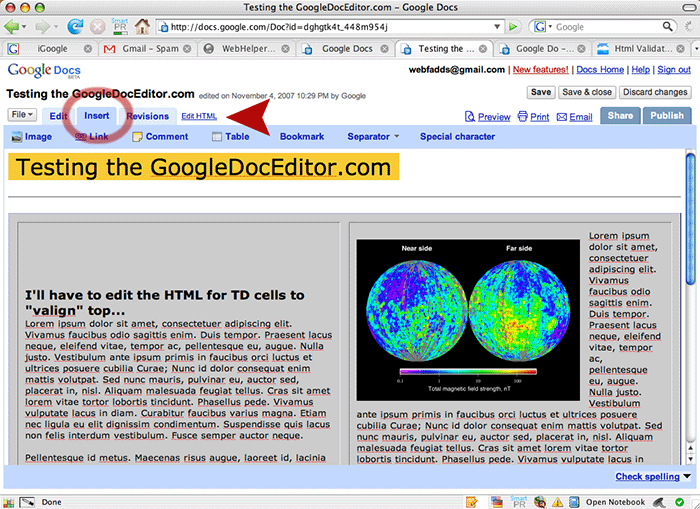
Note the tab controls at top left. To insert images and tables, you first click the “Insert” tab to access those controls.
3. You take a look at the HTML… a run-on mess with no DocType declaration, header or body tags:
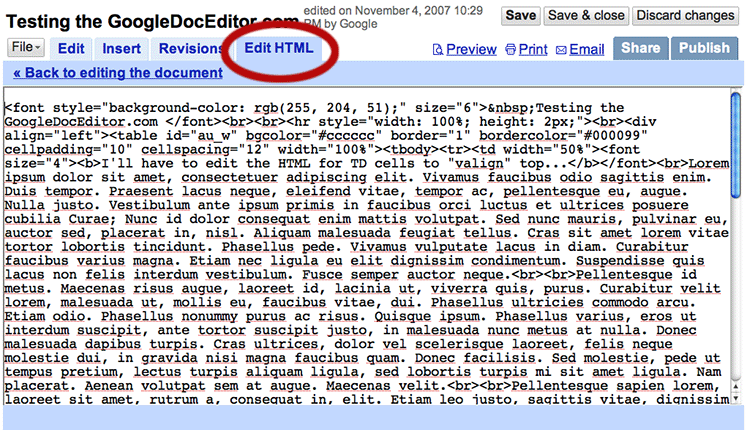
This view is accessed by clicking the “Edit HTML” tab at top left. Sure, if you understand HTML you can read this, but it would be nice to have line numbers and properly structured code.
4. To confirm it’s an unvalidated mess, we first click “Preview” (not “Publish” unless you are ready to place your document online) to see the document as a web page (Google allows you to “publish” web pages right from Google Docs), then run the HTML validator on it using the Web Developer toolbar in FireFox (alternatively, you could jump over to the online validator at W3C.org, and input the URL for the Google page you have made).
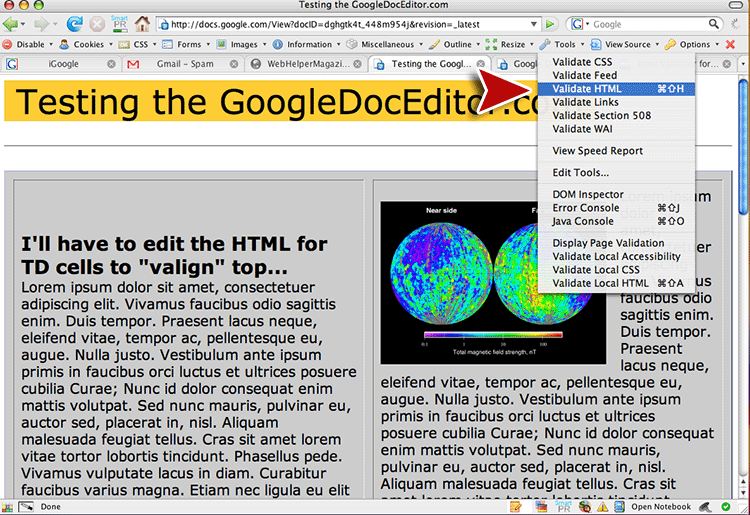
First we use the Web Developer extension for FireFox [http://chrispederick.com/work/web-developer/] (essential for every Open Source WebMaster to have in their tool kit) to select Tools Validate HTML.
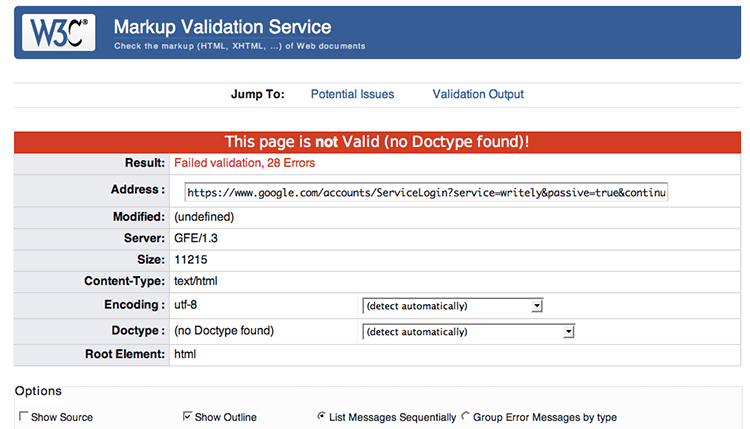
The Validator makes a point to note there is no doctype declared, and then lists 28 Validation Output errors by line number. A careful read of the Validator results shows a number of problems, some which are in code which Google slaps into your document, but did not show you when you viewed the document under “Edit HTML.”
5. To clean the code, we’ll use HTML Validator FireFox extension that puts some teeth in the VIEW>Source dialog and actually allows you to clean your code. If you’re following along, you’ll need FireFox, or a Mozilla browser, with the HTML Validator Extension pre-installed.
6. View the page in preview mode again, then select View»Page Source from the main menu at top:
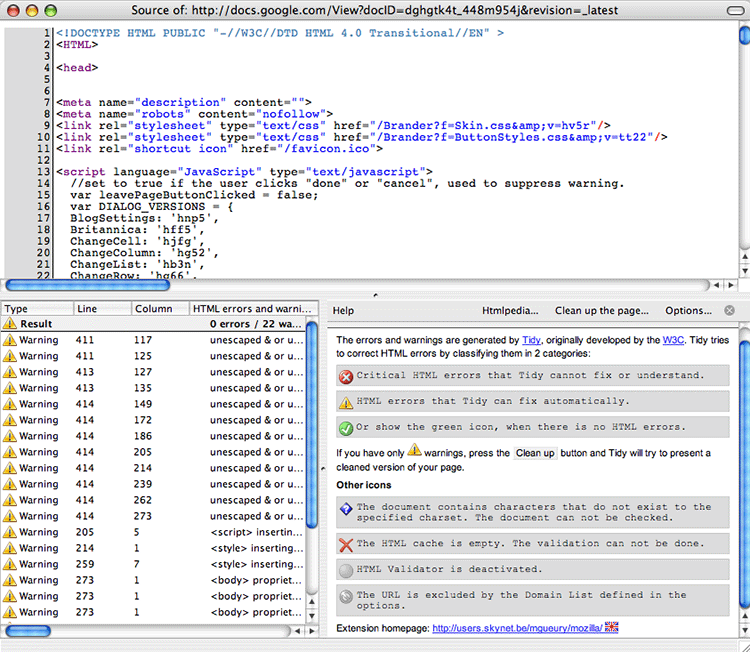
Thanks to the HTML Validator extension, we now have a WebMasters view of the document with line numbers and some excellent clean-up options. The large window at top shows the source code with the additions from our friends at Google, while the bottom left window shows warnings which the “Tidy” program built into the extension can fix. Note that at times it may show errors it cannot fix.
* Note also that Tidy located 22 errors, while the W3C validator identified 28. Why? That’s because we’re showing the code cleaning option using the Tidy Parser, while the W3C program uses the SGML parser. But you get to choose which one to use. I like the Tidy Parser, even though it doesn’t “agree” with the W3C, because it offers the feature to “clean up the page.”
7. Next we’ll choose “Clean up the page” — your time saving trick.
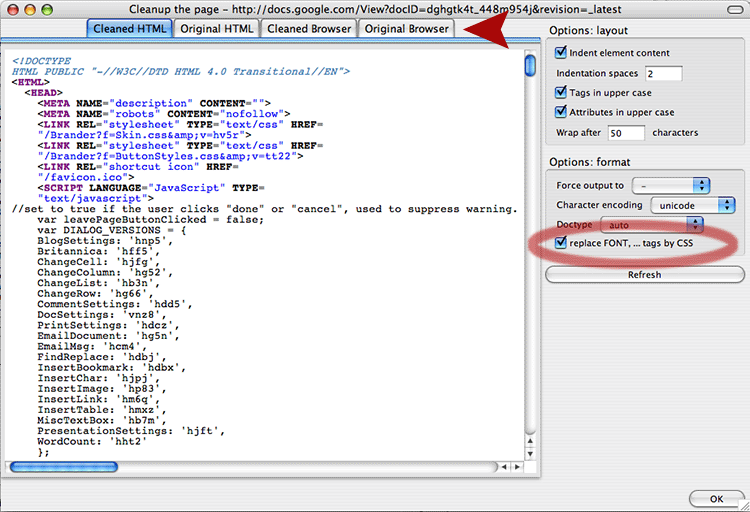
You click “Clean up the code”, then the dialog box you see above with your “cleaned code” appears, courtesy of Tidy. Nice. Note that this view allows you to compare the original source code to the cleaned code and also see how it looks in browser views (top row of buttons). Keep “replace FONT tags by CSS” checked (bottom right), if you want the program to generate a nice internal style sheet for you.
8. Once the page is “clean” (according to Tidy), then I recommend you paste the cleaned code into your “real” webmaster editing program. Remove any unwanted Google code. You’ll see that Google places a number of links to external style sheets, and some JavaScript in your code (a lot of which has to do with the ability to edit your document using Google Docs) which you may simply delete. Note that at this writing, Google also pasted in code to tie your page into Google Analytics — a blow your mind/comprehensive statistics tool — you may wish to leave that in.
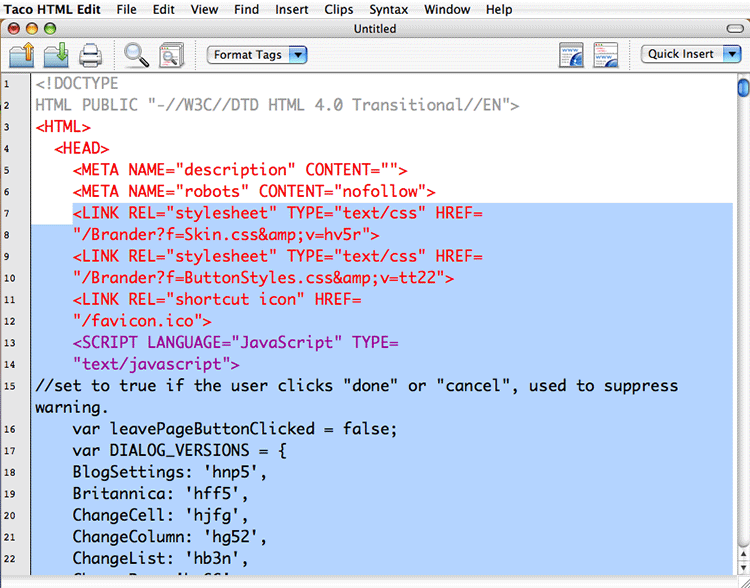
Above is a shot of my Editing program (“Taco HTML Edit” — excellent, and free for Mac users… http://tacosw.com/) with some of the code that I later removed, highlighted in blue. This program has a built in validator I could use for my final check, but I’ve included the following step — Step 9 — to indicate preferred use of the W3C.org’s validator… unless you know that your editing program already uses that validator.
9. Then validate your page once again using the W3C.org validator, and make the final changes by hand (you don’t want the machines to render you useless, do you?). For my page with a headline, a table and some copy… I now only have 6 errors, mostly having to do with how the table was coded — all easy, quick fixes.
Here’s the list of the final errors, for your reference:
* Line 77, Column 18: there is no attribute "TOPMARGIN".
BODY TOPMARGIN="0" RIGHTMARGIN="0" LEFTMARGIN=
* Line 77, Column 34: there is no attribute "RIGHTMARGIN".
BODY TOPMARGIN="0" RIGHTMARGIN="0" LEFTMARGIN=
* Line 78, Column 2: there is no attribute "LEFTMARGIN".
"0" BOTTOMMARGIN="0"
* Line 78, Column 19: there is no attribute "BOTTOMMARGIN".
"0" BOTTOMMARGIN="0"
* Line 87, Column 8: there is no attribute "BORDERCOLOR".
"#000099" CELLPADDING="10" CELLSPACING=
* Line 259, Column 8: end tag for "DIV" omitted, but its declaration does not permit this.
´/BODY
* Line 85, Column 6: start tag was here.
´DIV CLASS="
The Bottom line (with some Q & A)…
The big question for webmasters is this: Is starting with Google docs to create a document worth the effort to “tidy” up your code for the web? The answer is definitely “yes” if you have more than one purpose for the document, and particularly so if that’s the best way to work with a client. I also like the ability to focus on writing first, and since Tidy cleans 80%-95% of the code problems automatically, there isn’t too much work I have to do in order to get this Google Doc writing advantage. Besides, at this key transition/update time (when will it end?), it is good to exercise your hand validation skills as a WebMaster of the 2,000’s.
Q & A…
- Where can I go to understand how Tidy “fixes” my documents? Take a good look at the user guide for the HTML Validator extension.
- Why are the code error results different in the Validator extension, than those reported at W3C.org’s validator? Again, the Validator example shown above shows results using the Tidy parser, while the W3C.org uses the SGML parser. You can set the “algorithm” to use either parser after clicking the “Options” link:
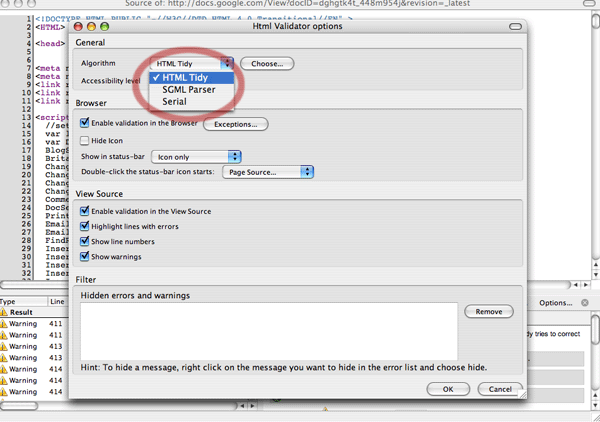 Here is a comparison table comparing features of the three choices you have for parser Algorithms in the Validator extension:
Here is a comparison table comparing features of the three choices you have for parser Algorithms in the Validator extension: At first I thought the Serial algorithm might be good choice (above right), but note that if there are errors, it does not open HTML Tidy, and therefor, no cleanup page option is provided.
At first I thought the Serial algorithm might be good choice (above right), but note that if there are errors, it does not open HTML Tidy, and therefor, no cleanup page option is provided. - Can you recommend some resources for understanding validation issues? Start with this surprisingly easy to read tutorial at W3C.org [http://www.w3.org/QA/2002/04/Web-Quality] (usually they write in a stuffier style).
- What should I know about “doctype” declarations? They’re important. Check out this article at AListApart [http://www.alistapart.com/articles/doctype/]. Then read the official lowdown from the big boys at the W3C.org., and check out their list of different doctypes [http://www.w3.org/QA/2002/04/valid-dtd-list.html ](bet you didn’t know there were that many!)
- Where did you get the heat map image of the Moon? I went to Wikipedia.org and looked up “Moon.” Then I selected an image that was not copyrighted, and in the public domain. Wikipedia is an excellent source for such images.
About the Author: Scott Frangos is a web developer, college instructor, illustrator, and graphic designer. He is Managing Editor for WebHelperMagazine, and is also writing two forthcoming books for Web Masters. He lives in Portland, Oregon with wife and partner, Pepper, and their three dogs: Wisdom, Spirit, & Steggman.